DC 28 CTF Postmortem
DEF CON CTF is one of the most important events in the community, and hosting it is both an honor and a great responsibility. To be true to this responsibility, the Order of the Overflow strives to be transparent about any and all mistakes that we make during the game. We understand that as organizers it is our responsibility and duty to create a fair game where the best hacking team wins. We absolutely hate when our mistakes impact the outcome of the game (which is almost inevitable as organizers: virtually all our mistakes inherently impact the outcome of the game), and every year we try to implement new internal testing procedures and measures to ensure that the same mistakes don’t happen again.
While some mistakes do not directly impact the game, we have certainly made mistakes that do. We will never forget when, on the last day of DEF CON 26, the captain of DEFKOR00T came up to the organizer’s table and calmly told us something along the lines of “Hey guys, we’ve been exploiting the reeducation service for about 45 minutes and all we get are flags full of zeroes.” Our blood ran cold as we scrambled to understand what the problem was as fast as we could. We let them know that we fixed the problem, they capped the flags and first blooded the service, and the game continued. Of course, we couldn’t retroactively go back and give teams flags, and they were understanding about this. This mistake clearly impacted the game.
We strive to be transparent with such mistakes, and disclose them all at the captain’s meeting before and after each period of play. For instance, in our first year, the scoring calculation was incorrect for two days, which caused defense points to be miscalculated and for teams not to know their actual place (thanks PPP for the heads up). Once we fixed the problem, we had a captain’s meeting where we showed the buggy code, explained what went wrong, and presented the new and correct scores. Likewise, DEFKOR00T’s aforementioned conundrum was thoroughly discussed at the next captains meeting.
During the course of DC 28 CTF, we kept the tradition of having a captain’s meeting over Discord to disclose mistakes and how we planned to fix them. The log of these mistakes is publicly available.
This year (DC 28 CTF), as in prior years, we made a number of mistakes that resulted in some players understandably feeling upset, however the tenor of displeasure this year reached a level that seemed higher than years past. Perhaps it was the narrow margin of victory, perhaps it was the fact that everything was remote so we couldn’t talk to each other face-to-face to explain/debug problems, or perhaps a little of both.
We understand the passion driving this response: We love that the CTF community is passionate about the game and plays to win. It is this passion and drive that pushes the CTF community to new heights. Hell, adamd has straight sobbed after losing close wrestling matches in high school (he wrote this and approves, don’t worry), and we’re all no stranger to passion and competition. However, it may be helpful for the community to look to other competitive communities like professional sports teams, which play at the highest levels of competition, with millions of dollars on the line, while respecting their opponents and the officials.
That said, we’d like to take this opportunity to dive into the major issues from DC28 that we’re aware of (we’re aware of a lot more, from both internal and external feedback), provide context on our side, take responsibility, and examine some take-aways.
6-Minute Blocking of Tea Deliverers
The challenge sloootmachine was a new type of challenge that we were experimenting with: how to have an attack-defense crypto challenge with algorithmic-level vulnerabilities. The short version was that the challenge was themed around white-box cryptography, and therefore teams needed to upload their own crypto modules to patch.
The challenge stated: “Your patched file should not be obfuscated,” because the goal of the challenge was not to create an obfuscated binary, but to create a correct white-box crypto implementation.
While the challenge was live, we were reviewing patches (not in-line before they were deployed, but as they came in) to see that this rule was followed. As you can imagine, it is quite time consuming to review all of these patches.
This rule is why when we received a ticket from a team claiming that Tea Deliverers had obfuscated their patch, we sprang into action. We superficially reviewed the patch, agreed with the assessment, then decided on a swift course of action: blocking Tea Deliverers from the game (similar to what we’ve done in years prior to teams that make too many requests per second to the system).
Since this was virtual, we then discussed with the Tea Deliverers captain, explaining what we saw, and asking them to revert the patch. They agreed and we let them back onto the game after ~6 minutes of disconnection, which was roughly the length of a tick in the game.
Later in the game, Tea Deliverers asked us directly via discord if upx was disallowed, along with other questions. After deliberating among ourselves, we decided that upx was fine because it can easily be undone, so we informed Tea Deliverers that we did not consider it obfuscation.
We found out after the game that the patch that Tea Deliverers originally submitted was not obfuscated but was packed using upx, and we failed to detect that.
Our major mistake here was blocking Tea Deliverers without reaching out to them for clarification. We ask that players assume that we are operating in good faith, and therefore we should assume that teams are operating in good faith. We apologize for that, and we’ll do better in the future.
Shift Four bdooos
A few major issues occurred during the last shift (shift four) around the service bdooos. We’ve received feedback and constructive criticism that we should do better at play testing services before releasing them, particularly if they are exotic or present other challenges. We’ve taken this feedback internally seriously, and we will do better. At this point, we’ll focus on three critical issues that were raised around bdooos. Our intention here is not to deflect blame from ourselves, but to clear the air so that everyone can know what was going on from our perspective, so that we can all agree that these were honest mistakes that we will work on preventing in the future.
Background: bdooos
During DEF CON 27, we brainstormed bdooos as a service concept based around dedicated hardware that the players would have in their possession for DEF CON 28, and wrote it as such. Dedicated hardware challenges are always unique and fun, and we were excited to deliver a cool challenge like this to the players.
Unfortunately, COVID hit, and DEF CON was “cancelled”. We pivoted from dedicated hardware in possession of teams to dedicated hardware hosted by us. We used a place with a solid internet connection (an academic office), and set up the infrastructure for that service. Unfortunately, COVID struck again: two days before the start of DEF CON 28, it turned out that OOO would be unable to access the office in which the hardware was deployed, due to COVID restrictions. In retrospect, this should have been the end of the challenge, but we felt that we could push this challenge to completion, and undertook a hard push to port it into the shape that was released in the end: rust binary, kernel, etc, all running on qemu.
Clearly, we could have done better. In the course of porting, some “extra” vulnerability paths were rendered unusable (the seccomp issue, referred to later in some of the tickets), and without the hardware that it was originally written for, the service did not make as much sense semantically.
Another source of confusion was SLA. In a traditional attack-defense CTF, the organizers run functionality checks throughout the game to ensure that teams do not break the functionality of their services. When these checks fail, teams lose points. This was always frustrating to us as players, so instead, OOO developed an on-deploy patch verification system, where patches would be verified for functionality, and patches that fail this check would simply not be deployed.
Unfortunately, this patch verification model is incompatible with how we developed bdooos, and as a last-minute solution, we shoehorned SLA back into the game just for this service: SLA checks would again be run, and teams that fail them would have their flags disclosed on the service’s web interface via an “SLA disclosure”. As discussed later, this caused some chaos.
Issue: bdooos Flag Location
A major issue with bdooos was that the service description said “Flag location: /flag”. This was incorrect due to technical issues. A*0*E asked us about the flag location at 11:44am.
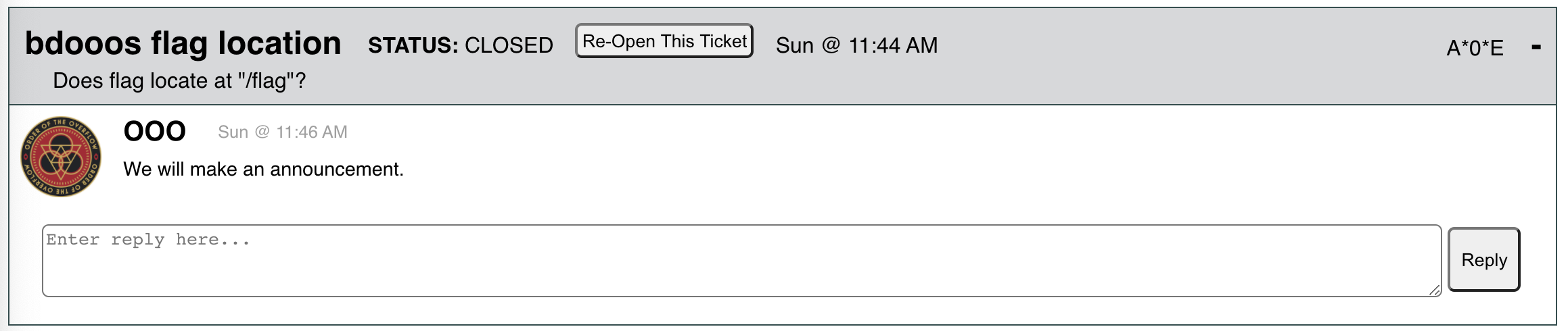
At this point we realized our mistake, and had to quickly decide what to do. We considered updating the code that generates the scoreboard to remove the flag location with a yaml flag, however we were worried about doing this quickly and introducing other breaking changes while trying to fix this. As will become clear shortly, such breaking changes are very much a real possibility.
We also considered directly editing the HTML text that is sent to the database for the service. However, if we reran our code, it is very likely that we would forget to make the change again and the appearance would revert. We could also have made the change directly on the DB (very risky), but for similar reasons decided not to do this.
Therefore, we decided to just notify the teams that the information about /flag was incorrect on the scoreboard.
To further contextualize the situation (and again, this is not to deflect blame from us—we absolutely made mistakes—more to provide context and how we learn from them going forward), at this point, it was 11:45am, and we were 15 minutes from our third live #ctf-discussion-voice update that we undertook this year to make DEF CON CTF more accessible to the general public.
Yan and Adam were discussing with the OOO team what should be done while they were gone, who would drop off the live update if there was a problem, and how to make the scores of the game go dark at 12pm.
Looking back it was a mistake to walk away from a live and running game, particularly a close one at the end while we were all remote.
At 11:48 am, we posted a notification in the team interface that bdooos flags are NOT located at /flag. We had mentioned to all the teams at the start of the game that we would mirror all announcements on discord, the team interface, and twitter. We didn’t have any automation in this regard, just a lot of manual copy-paste (in part because we didn’t have time to finish configuring our Discord setup until Friday at 3:30am, 30 minutes before the first shift). In this instance, the person doing this simply forgot and didn’t mirror the notifications to discord, nor twitter.
Unfortunately we didn’t realize that we messed up and did not propagate that message everywhere until we received this ticket from PPP:
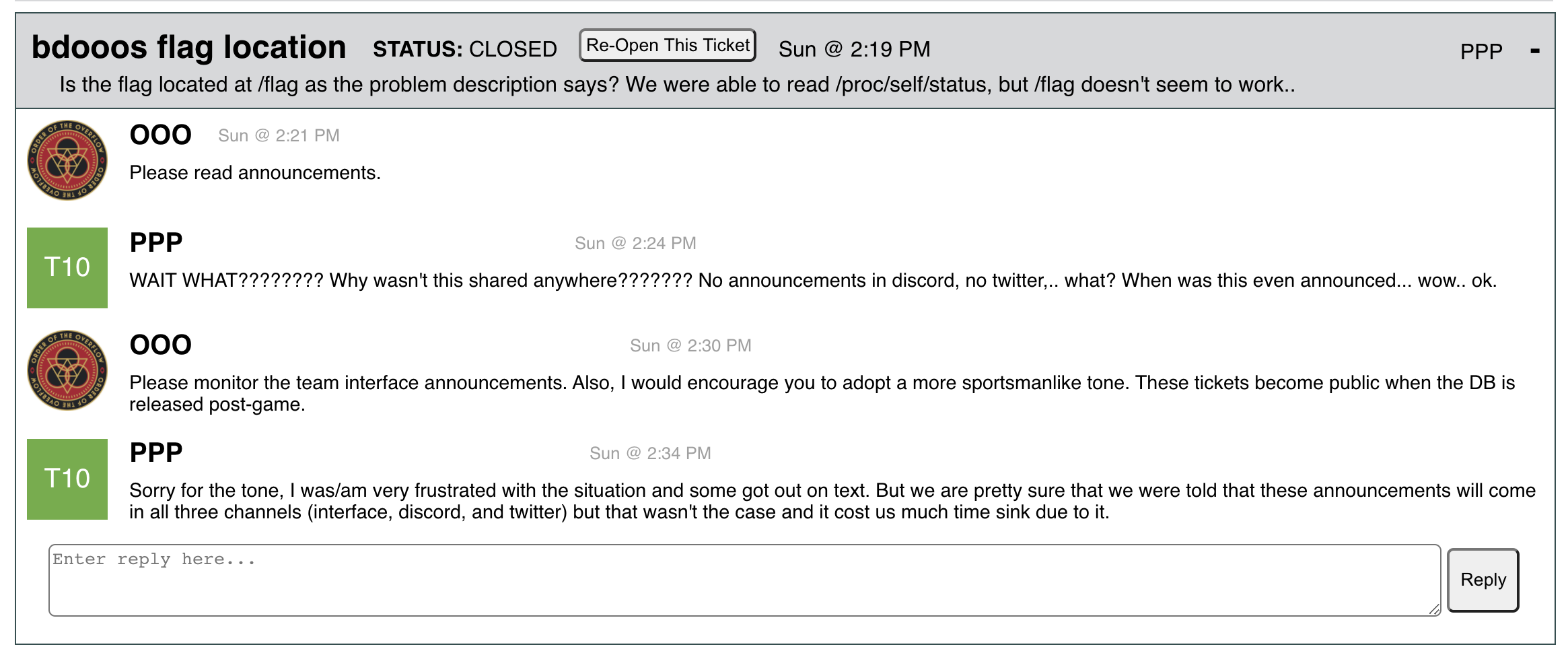
There’s a lot of things going on here. We should have apologized on this ticket for not propagating this notice to all the announcement channels (we mistakenly assumed that the announcement went out through the usual channels), and we did mention this issue during the captain recap. We also should have assumed more good faith on PPP’s part and started to question why a top team would have missed our announcement.
It’s important to note that we made a mistake by not propagating that announcement, and that this mistake almost certainly would not have happened in an in-person CTF. Zardus would grab the mic, announce “Attention teams” in a too-loud-volume-even-though-we-beg-him-not-to voice, and all teams would check their team interface. We also wouldn’t have a need for multiple announcement channels at an in-person CTF. The lack of a high-level interrupt like the mic, in this case, caused this announcement to be missed.
Root Cause
bdooos was a special service, and so we tried to use as much of the existing infrastructure as possible to help with the creation. As a result, internally, bdooos was actually two services: the information-hosting web server that teams accessed to get endpoint information and SLA flag disclosures, and the actual service. The flag location that the teams saw was actually relative to the information page that they accessed, and another internal service would run and shuttle those flags to the bdooos instance.
We failed to double check the bdooos scoreboard before deploying to ensure that what was shown to the teams was correct. We actually had a similar problem with rhg before the game started, because rhg also used a slightly non-standard central server configuration emulated through an extra helper service. We fixed rhg before deployment, but we failed to realize that bdooos was similar.
Issue: bdooos Stale Flags
Another major issue was that the bdooos service was not setting flags properly from the start of the fourth shift.
During shift three, when bdooos was released, running, and properly setting flags, a number of teams reported tickets saying that they captured a stale flag. We looked intently into this issue, and realized that the service would have old flags around from after when a team failed SLA checks. This means that if a team failed SLA checks at tick A, then fixed it, at tick A+3 the flag for tick A would be available, however it was now stale (from the game’s perspective). Therefore, from our perspective when a team reported stale SLA flags, the service was working as intended.
Shift four then started, and after several hours of gameplay PPP submitted this ticket regarding stale flags for bdooos:
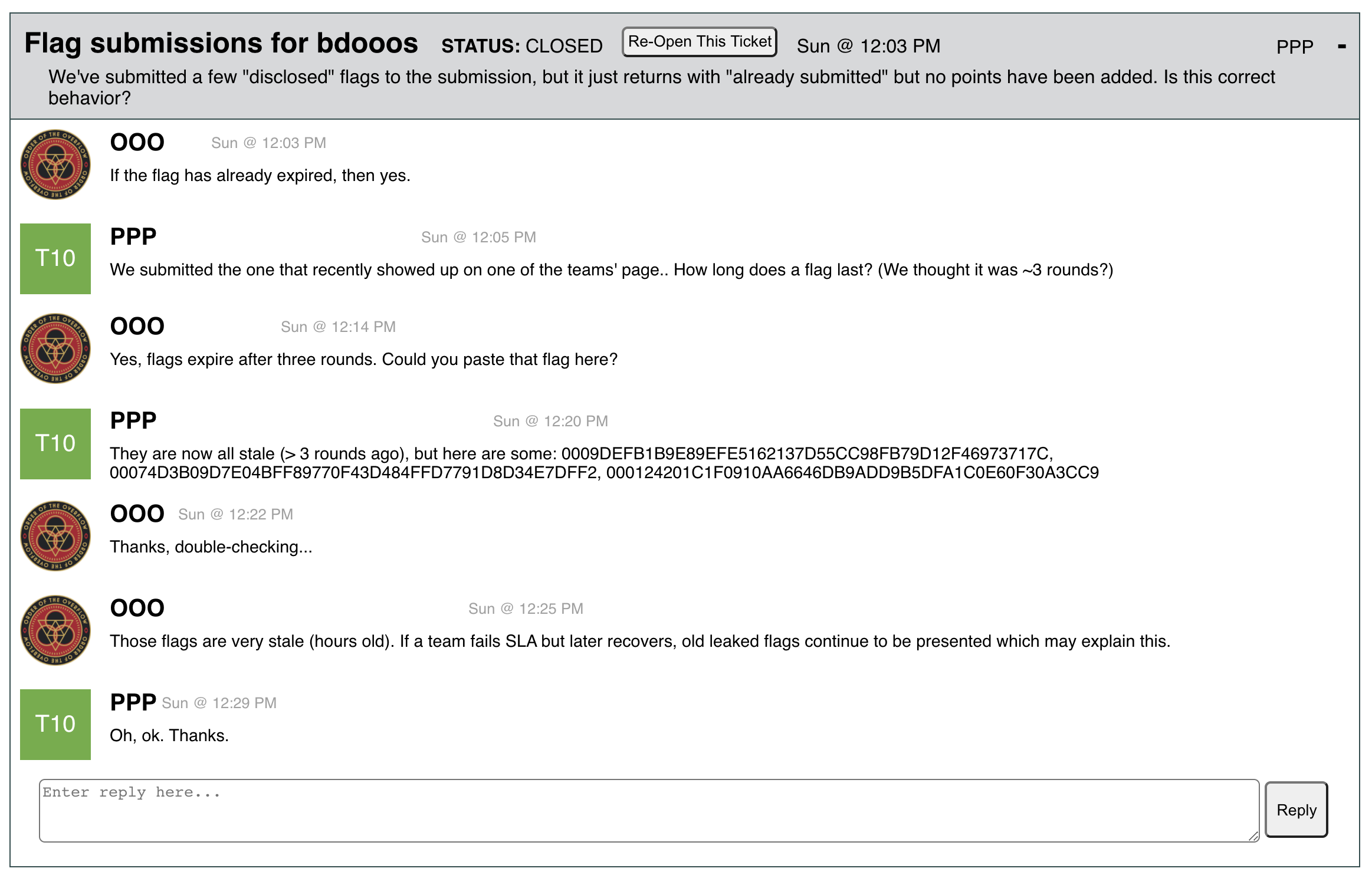
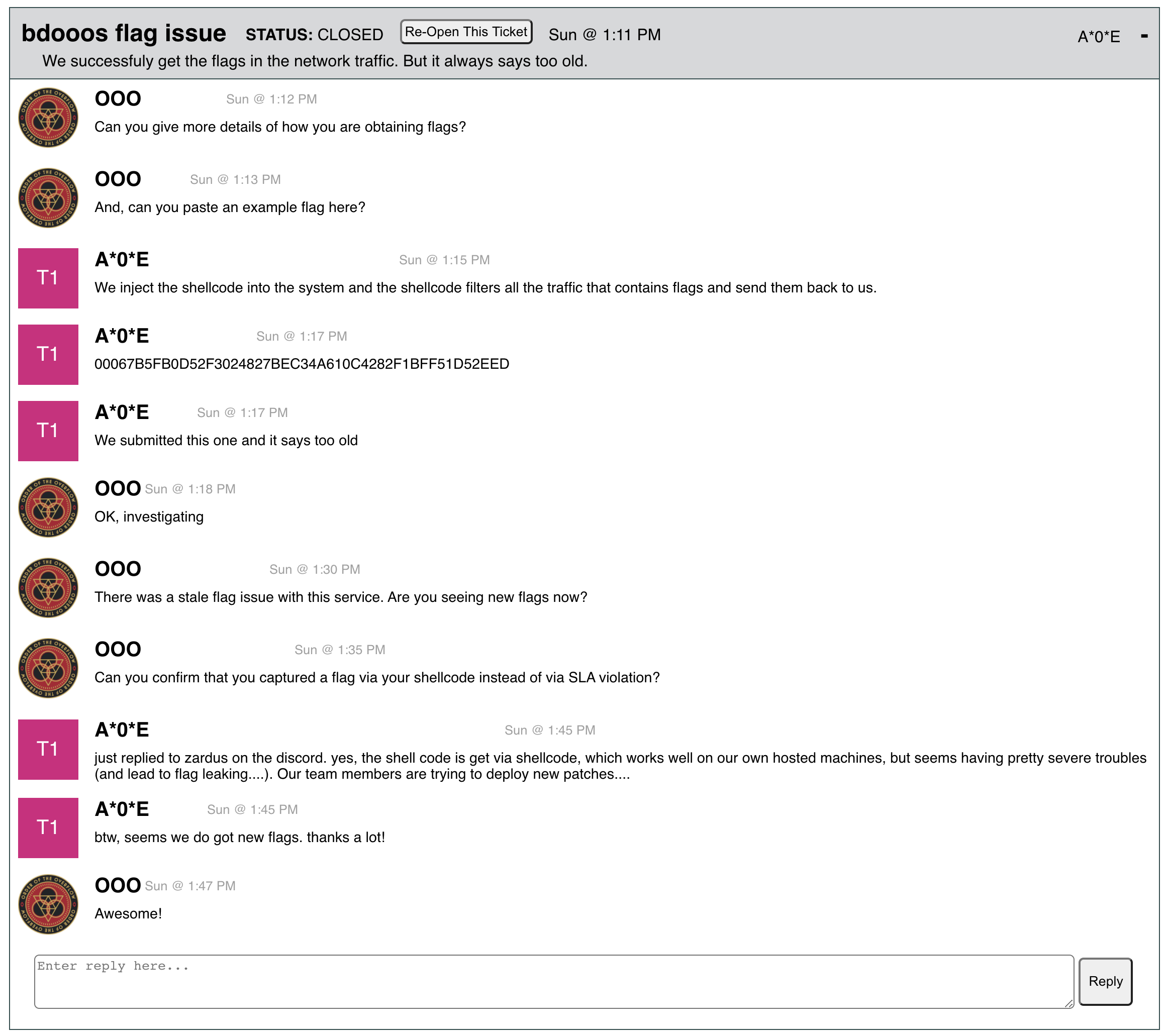
From our perspective at the time, based on the word “disclosed”, we assumed that this was referring to stale SLA flags. An indication that this was not the case (that we missed at the time) was the response from PPP saying that it “recently showed up”, which should have indicated to us that flags were stale.
We messed up, and we should have looked into this issue or followed up with PPP. We believe that if we were in person we could have ironed out this issue quickly.
About an hour later we received another report from A*0*E, and from this we made an announcement that “bdooos clarification: disclosed flags remain disclosed until the next SLA violation.”
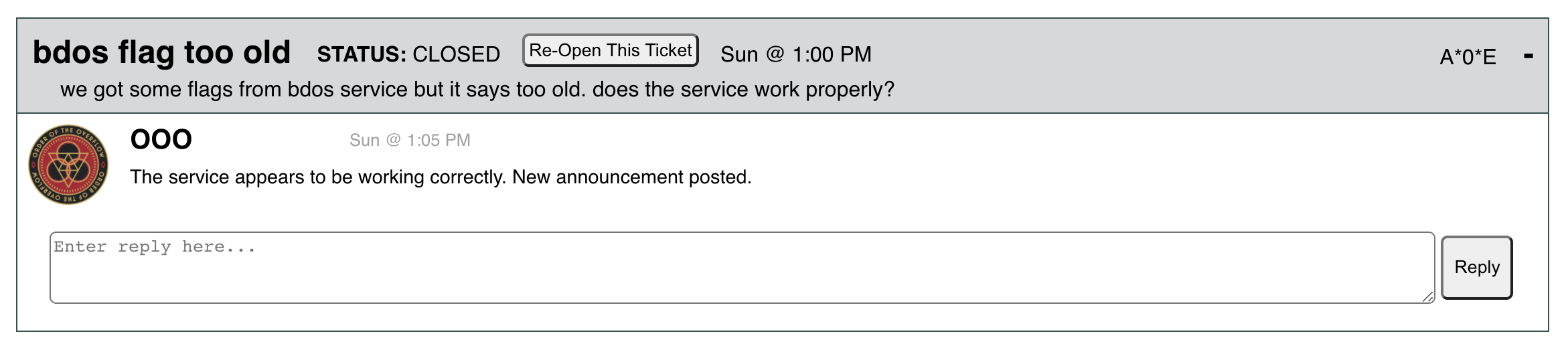
Eleven minutes later, A*0*E opened a new ticket essentially saying that they were exploiting the service and not getting flags. This set off the alarm bells as we frantically tried to identify and fix the bug (see root cause analysis in the next section if you’re interested).
Besides the technical failure here (discussed next), we failed to take reports of stale flags seriously, thinking instead that this was (similar-looking, but subtly different) intentional functionality of the service, and we failed to follow up with teams to clarify what they meant in the case of these stale flags. We apologize to all the teams, particularly PPP and A*0*E as it appears they were directly affected.
Root Cause
The underlying root cause of the technical aspects of this issue was that the service author merged in the latest version of our challenge template (which is something that we encourage challenge authors to do), which resulted in a bad git merge that duplicated the isolation levels to the challenge’s info.yml (changing it from shared to private). This was done in the course of investigating whether to “fix” an extra vulnerability path that we had realized had been accidentally broken during the port of the service away from dedicated hardware. When this change was applied to the DB right before the start of the fourth shift (the person deploying the DB change didn’t catch it either), we failed to check that the attributes of the service were correct. This means that the flag setting system did not set the flags on the right instances. We also assumed that because flags were set during the third shift for bdooos (evidenced by the teams submitting SLA fail flags), that this isn’t something that we should retest. Another failure on our part.

Based on our experience with stale flags at DC26 CTF, we added a stale flag checker to the system for DC27 CTF, which to our recollection prevented any stale flags. However, this year, due to internal team communication failures, we thought that the stale flags checker was running for all services but it was not, so we didn’t detect the stale flags and fix the issue.
This has highlighted the need to have a tested and repeatedly verified game component that’s sole job is double checking that there are no stale flags on a service.
bdooos functionality discussion
This issue doesn’t quite have a nice technical solution, so it’s something the community can think about how to address for fairness in a high-level competition. In an effort to provide a fair game, we very much strive to not provide hints. Those that have run high-profile CTFs know the term “fuzzing the organizers”, where a team/players on a team will ask the org or the specific challenge admin questions about a service in order to leak information. This heavily biases the CTF toward teams that have the best skills in a common language with the organizers (in this case, mostly English).
To combat this, we adopt a strict “no-hints” policy for quals, particularly after a challenge is solved. If we provide a hint after a challenge is solved, that that is unfair to the teams that solved it before without the hint (maybe they could have solved it quicker with the hint and had more time for other challenges).
We adopted a similar style for finals (which we are reconsidering going forward, given how much frustration this added to the teams), and this results in some awkward communication with teams, particularly over text. We reply terse and curt not to be mean or dismissive, but because we do not want to leak information to one team over another.
This style was particularly difficult to maintain for bdooos, given the complexity of the service.
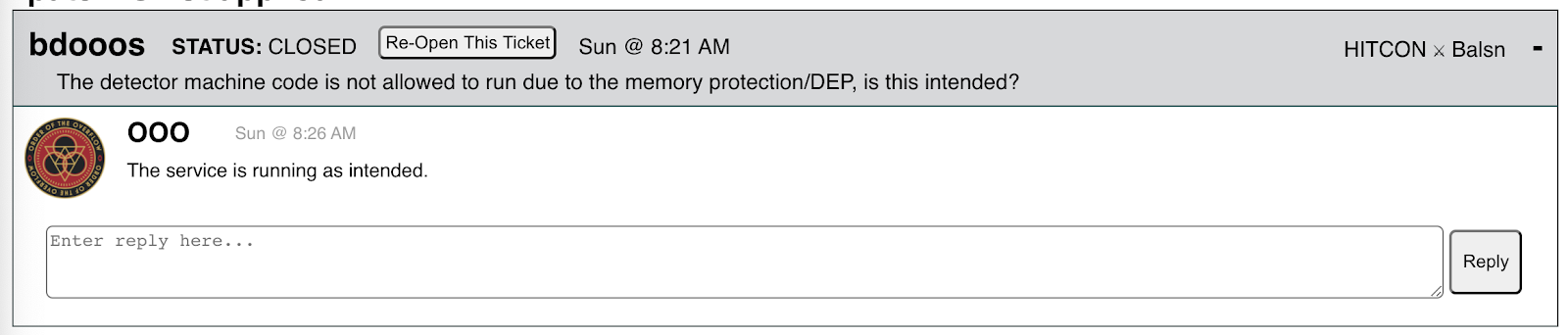
For instance, when we receive questions about bdooos, we usually say that the service is running as intended:
We realize now with feedback from the teams that this feedback sent them down the wrong path, for instance, with this ticket from PPP:
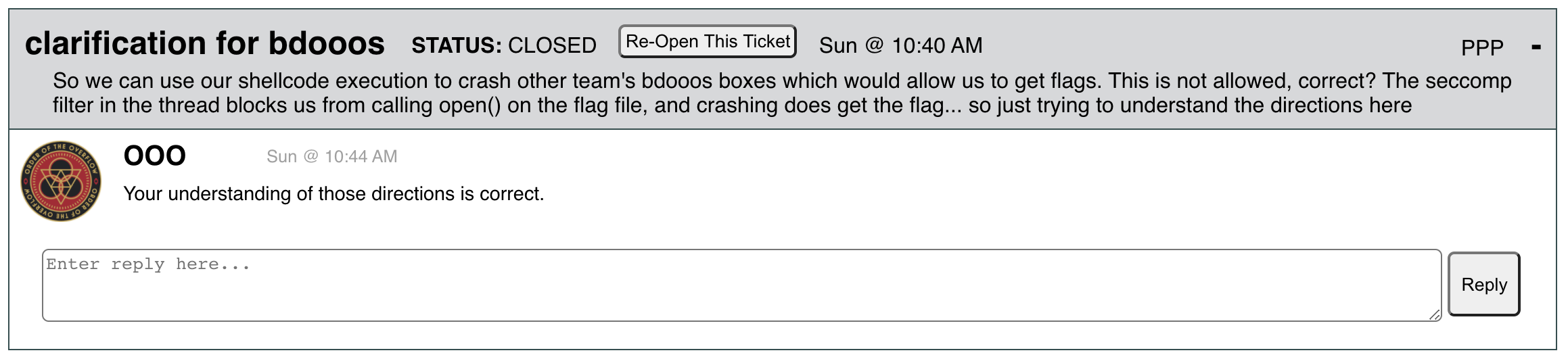
From our perspective, we didn’t want to say something like “If you crash other teams bdooos boxes, you will get a flag because their machine failed SLA checks, but everyone else will get the flag as well, so it’s pointless to do so.” Our general mistake here was to not clarify the DOS policy for everyone, which was not clear to all the teams (in this case, as we responded, an intentional DOS of this kind was against the policy, while an accidental DOS while testing shellcode would be OK).
We are looking into a number of solutions for this, going forward. One idea that we had internally, and was also suggested by several teams, is to make all tickets public by default. We have other ideas as well, and we hope that this aspect of the competition will be better in the future.
Impact on the Result
It is hard to speculate the exact impact these issues had on the CTF. A team might say “We would have gotten X place if Y had been different”, but the truth is, if Y were different, then it would be different for everyone. Our first year, a team got extremely and publicly upset over a service that was too CPU-intensive to function properly in our infrastructure. It was relayed to us that they felt that, had this service worked properly, they could have done better in the game. From their perspective, this issue hurt their performance the most, but they actually were not the first to develop an exploit for that service, and were almost certainly not the worst-impacted.
Likewise, it is hard to speculate what would have been different without the issues that we encountered in bdooos. Ultimately, the game would have been different for all teams involved, and this is not something that we can go back and fix. And, importantly, all of this should not take away from the excellent A*0*E victory. This was a well-fought battle, and they should savor the win, until next year rolls around and the fight commences anew.
Among the members of the Order of the Overflow, we have well over a cumulative century of experience competing in CTF, under almost every organizer. A lifetime ago, Zardus once worked on not one, but two challenges during a CTF that never ended up being scored at all due to organizer error. This was unfortunate and upsetting, but it was clearly never done to single out one team, and the fairness of that competition was maintained as much as possible.
Recap
If you made this far, then thanks for reading. We hope that this shows that the mistakes and communication mishaps that we made were honest ones. We apologize for frustration that you experienced during the game that was not related to reversing challenges or popping shells, and we will work on improving the game year-over-year. Your feedback is always welcome as we, as a community, can improve and enhance DEF CON CTF together.